1.1 kubernetes集群组件概述
Kubernetes 集群由 Master 节点(控制节点)和 Node 节点(工作节点)组成,各自包含以下核心组件:
1.1.1 Master节点
- etcd
- 分布式键值存储数据库,保存集群的所有状态和配置数据(如 Pod、Service、Namespace 等)。
- 是 Kubernetes 的"唯一真实数据源"(Single Source of Truth)。
- API Server(kube-apiserver)
- 集群的入口,提供 REST API,处理所有操作请求(如创建、更新、删除资源)。
- 负责与其他组件通信(如 kubelet、kube-scheduler 等)。
- Scheduler(kube-scheduler)
- 监听未调度的 Pod,根据资源需求、节点负载等因素,将 Pod 分配到合适的 Node 上运行。
- Controller Manager(kube-controller-manager)
- 运行一系列控制器,确保集群状态与期望一致。
- 核心控制器包括:
- Node Controller(监控节点状态)
- Deployment Controller(管理副本数)
- Service Controller(管理 Service 与 Endpoint)
- 其他控制器(如 ReplicaSet、Namespace 控制器等)。
- (可选)Cloud Controller Manager
- 当集群运行在公有云环境时,负责与云平台交互(如负载均衡、存储卷、节点管理)。
- 解耦 Kubernetes 与特定云厂商的代码。
1.1.2 Node 节点组件
- kubelet
- 运行在每个 Node 上的"节点代理",负责:
- 与 Master 通信,接收 Pod 定义(通过 API Server)。
- 管理 Pod 生命周期(启动、停止、监控容器)。
- 上报节点状态(如资源使用、Pod 状态)到 Master。
- 运行在每个 Node 上的"节点代理",负责:
- kube-proxy
- 维护节点上的网络规则,实现 Service 的抽象(如负载均衡、服务发现)。
- 通过 iptables/IPVS 或用户空间代理转发流量到 Pod。
- 容器运行时(Container Runtime)
- 负责运行容器的底层软件,如 Docker、containerd、CRI-O。
- 与 Kubernetes 通过 CRI(Container Runtime Interface)交互。
1.2 集群主机规划
假设我们只有3台主机,为了兼顾硬件条件限制而搭建高可用集群,以下是较为合理的集群软硬件规划:
节点名称 | IP | 操作系统 | 配置 |
k8s-101 | 192.168.122.101 | Debian GNU/Linux 12 (bookworm) | 内存:4G + SSD硬盘:30G + CPU:2核 |
k8s-102 | 192.168.122.102 | Debian GNU/Linux 12 (bookworm) | 内存:4G + SSD硬盘:30G + CPU:2核 |
k8s-103 | 192.168.122.103 | Debian GNU/Linux 12 (bookworm) | 内存:4G + SSD硬盘:30G + CPU:2核 |
这三台主机在集群中分别充当的角色如下:
节点名称 | etcd服务器 | 控制节点 | 工作节点 | L4/L7代理 | 额外角色 | |
k8s-101 | ✓ | ✓ | ✕ | ✓ | 签发证书节点、主要控制节点 | |
k8s-102 | ✓ | ✓ | ✓ | ✓ | ||
k8s-103 | ✓ | ✓ | ✓ | ✕ | ||
以上是在资源有限的情况下做的高可用资源分配,搭建集群的过程,其实就是把集群的各个软件组件合理安装到不同主机上,并且保证各个组件能正常工作。如果你的服务器资源充足,应当将组件独立部署到更多主机上,达到增强性能、可用性、可扩展性的目标,简化维护并增强安全性。
1.3 设置hostsname
在 192.168.122.101 执行以下命令
hostnamectl set-hostname k8s-101
cat >> /etc/hosts <<EOF
192.168.122.101 k8s-101
EOF
在 192.168.122.102 执行以下命令
hostnamectl set-hostname k8s-102
cat >> /etc/hosts <<EOF
192.168.122.102 k8s-102
EOF
在 192.168.122.103 执行以下命令
hostnamectl set-hostname k8s-103
cat >> /etc/hosts <<EOF
192.168.122.103 k8s-103
EOF
1.4 关闭交换分区
kubernetes 默认不支持在启用交换分区的情况下运行,可以编辑 /etc/fstab 文件,注释掉或删除与交换分区相关的行。然后运行以下命令确保交换分区被禁用:
swapoff -a
containerd 的下载网址为https://containerd.io/downloads/,在撰写文章时(2025.02.15)最新版本是 v2.0.2,我们将其安装到所有主机上,并作为容器运行时环境,安装步骤如下
2.1 安装 containerd
从 https://github.com/containerd/containerd/releases 下载 containerd-<版本>-<操作系统>-<架构>.tar.gz 存档,验证其 sha256sum,并将其解压到 /usr/local 目录下
# 下载并解压
tar Cxzvf /usr/local containerd-2.0.2-linux-amd64.tar.gz
# 创建并配置 containerd.service
mkdir -p /usr/local/lib/systemd/system/
cat > /usr/local/lib/systemd/system/containerd.service <<EOF
[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target dbus.service
[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerd
Type=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not supports it.
# Only systemd 226 and above support this version.
TasksMax=infinity
OOMScoreAdjust=-999
[Install]
WantedBy=multi-user.target
EOF
# 重新加载 systemd
systemctl daemon-reload
# 启动并启用 containerd 开机启动
systemctl enable --now containerd
2.2 安装 runc
runc 是一个轻量级的容器运行时工具,负责根据 OCI(Open Container Initiative) 规范创建和运行容器。containerd 依赖 runc 来实际启动和管理容器。
从 https://github.com/opencontainers/runc/releases 下载 runc.<架构> 二进制文件,验证其 sha256sum,并将其安装为 /usr/local/sbin/runc。
# 安装
install -m 755 runc.amd64 /usr/local/sbin/runc
该二进制文件是静态构建的,应该适用于任何对应架构的 Linux 发行版。
2.3 安装 CNI 插件
CNI(Container Network Interface) 插件用于配置容器的网络,包括分配 IP 地址、设置网络接口、配置路由等。从 https://github.com/containernetworking/plugins/releases 下载 cni-plugins-<操作系统>-<架构>-<版本>.tgz 存档,验证其 sha256sum,并将其解压到 /opt/cni/bin 目录下,操作过程如下
mkdir -p /opt/cni/bin
tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.6.2.tgz
将 /opt/cni/bin 目录添加到 $PATH 中,执行以下命令追加到 /etc/profile 文件中
echo 'export PATH=$PATH:/opt/cni/bin' >> /etc/profile
source /etc/profile
创建 CNI 配置文件目录
mkdir -p /etc/cni/net.d
cat > /etc/cni/net.d/10-mynet.conf <<EOF
{
"cniVersion": "0.4.0",
"name": "mynet",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.22.0.0/16",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
EOF
重启 containerd
systemctl restart containerd
这些二进制文件是静态构建的,应该适用于任何对应架构的 Linux 发行版。
2.4 使用命令行工具
containerd 是一个强大的容器运行时,但它本身是一个守护进程,需要通过命令行工具(CLI)来交互。不同的 CLI 工具(如 ctr、nerdctl、crictl)是为了满足不同用户和场景的需求而设计的。以下是它们的区别和适用场景:
工具 | 目标用户 | 功能特点 | 适用场景 |
|
|
| 开发和调试 |
| 普通用户和运维人员 | 类似 Docker 的体验,功能丰富 | 日常容器管理、生产环境 |
| Kubernetes 管理员和开发者 | 针对 CRI 设计,适合 Kubernetes 环境 | 调试 Kubernetes 节点和容器运行时 |
在这里,nerdctl 工具更适合我们的使用场景,因此选择 nerdctl。在 https://github.com/containerd/nerdctl/releases 下载对应的操作系统版本,在撰写这本文时 nerdctl 的版本是 v2.0.3,安装命令如下
wget https://github.com/containerd/nerdctl/releases/download/v2.0.3/nerdctl-2.0.3-linux-amd64.tar.gz
tar -zxvf nerdctl-2.0.3-linux-amd64.tar.gz -C /usr/bin/ nerdctl
最后,加载 nerdctl 的 Bash 自动补全功能,并设置 containerd 默认的名称空间为 k8s.io,如下
# 追加配置
cat >> /etc/profile <<EOF
source <(nerdctl completion bash)
export CONTAINERD_NAMESPACE=k8s.io
EOF
# 让配置立即生效
source /etc/profile
2.5 配置 containerd
containerd 默认配置文件在 /etc/containerd/config.toml,通过运行以下命令生成一个默认配置文件:
mkdir -p /etc/containerd
containerd config default > /etc/containerd/config.toml
重启 containerd
systemctl restart containerd
3.1 安装证书工具
cfssl 系列工具是 Cloudflare 提供的 PKI/TLS 工具,用于证书管理。可以在 https://github.com/cloudflare/cfssl 找到对应的信息,在撰写文章时版本是 1.6.6,我们下载对应操作系统的版本,安装到 k8s-101 这台主机,以 linux amd64 为例安装命令如下
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.5/cfssl_1.6.5_linux_amd64 -o /usr/local/bin/cfssl
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.5/cfssljson_1.6.5_linux_amd64 -o /usr/local/bin/cfssljson
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.5/cfssl-certinfo_1.6.5_linux_amd64 -o /usr/local/bin/cfssl-certinfo
chmod a+x /usr/local/bin/cfssl*
以下是它们的简要功能
工具 | 功能 |
cfssl | 核心工具,用于证书生成和管理 |
cfssl-json | 辅助工具,用于解析 JSON 输出 |
cfssl-certinfo | 用于查看证书详细信息 |
3.2 k8s所需证书概述
在 Kubernetes 集群中,我们需要为集群中的各个组件生成证书,以实现安全通信和身份验证。下图展示了 Kubernetes 所需的主要证书
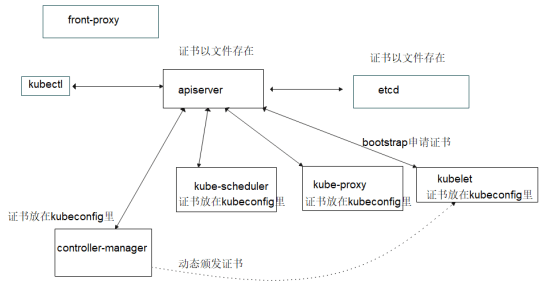
我们将在 k8s-101 生成的各个证书存放到 /etc/kubernetes/pki 里,并同步到其他主机上。
3.3 搭建CA
CA 是证书的签发机构的简称,所有子证书的签发证书的前提是有一个签发机构,下文我们搭建自己的签发机构。
使用以下命令生成 CA 配置
mkdir -p /etc/kubernetes/pki
cat > /etc/kubernetes/pki/ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "175200h"
},
"profiles": {
"www": {
"expiry": "175200h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
使用以下命令生成 CA 请求文件
cat > /etc/kubernetes/pki/ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Guangzhou",
"ST": "Guangdong",
"O": "kubernetes",
"OU": "system"
}
],
"ca": {
"expiry": "175200h"
}
}
EOF
证书根字段备注如下
字段 | 描述 | 示例或说明 | |
| 证书名称(Common Name),一般使用域名 | example.com | |
| 定义证书类型, | algo: RSA, size: 2048 | |
| 定义证书的通用名称,可以有多个条目 | ||
| Common Name,一般使用域名 | example.com | |
| Country Code,申请单位所属国家,只能是两个字母的国家码 | CN(中国) | |
| State or Province,省份名称或自治区名称 | Beijing | |
| Locality,城市或自治州名 | Beijing | |
| Organization name,组织名称、公司名称 | Example Inc. | |
| Organization Unit Name,组织单位名称、公司部门 | IT Department | |
| 代表有效时间,175200h 对应 20 年 | 175200h | |
最后使用以下命令生成CA自签名根证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
最后一个参数指定了证书文件名,最后生成以下三个文件
ca.csr: 证书签名申请(Certificate Signing Request)文件ca.pem: ca公钥证书ca-key.pem: ca私钥证书
生成的三个文件是根证书包含的内容。后续,我们给各个服务颁发证书的时候,都基于 CA 根证书来颁发。
3.4 签发证书
- etcd
定义证书信息如下
cat > /etc/kubernetes/pki/etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.122.101",
"192.168.122.102",
"192.168.122.103"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "CN",
"ST": "Guangdong",
"L": "Guangzhou",
"O": "kubernetes",
"OU": "system"
}]
}
EOF
支持的主机列表对应本机以及所有 etcd 节点。使用以下命令生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www etcd-csr.json | cfssljson -bare etcd
- kube-apiserver
k8s 的其他组件跟 apiserver 要进行双向 TLS(mTLS) 认证,所以 apiserver 需要有自己的证书,以下定义证书申请文件
cat > /etc/kubernetes/pki/apiserver-csr.json <<EOF
{
"CN": "apiserver",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"10.96.0.1",
"192.168.122.100",
"192.168.122.101",
"192.168.122.102",
"192.168.122.103",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"names": [{
"C": "CN",
"ST": "Guangdong",
"L": "Guangzhou",
"O": "kubernetes",
"OU": "system"
}]
}
EOF
该证书后续被 kubernetes master 集群使用,需要将 master 节点的 IP 都填上,同时还需要填写 service 网络的第一个IP(后续计划使用10.96.0.0 255.255.0.0 网段作为 service 网络,因此加上 10.96.0.1),后续可能加到集群里的IP也需要都填写上去。最后使用以下命令生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www apiserver-csr.json | cfssljson -bare apiserver
– kube-controller-manager
controller-manager 需要跟 apiserver 进行 mTLS 认证,定义证书申请文件如下
cat > /etc/kubernetes/pki/controller-manager-csr.json <<EOF
{
"CN": "system:kube-controller-manager",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.122.100",
"192.168.122.101",
"192.168.122.102",
"192.168.122.103"
],
"names": [
{
"C": "CN",
"ST": "Guangdong",
"L": "Guangzhou",
"O": "system:kube-controller-manager",
"OU": "system"
}
]
}
EOF
hosts 列表包含所有 kube-controller-manager 节点 IP;CN 为 system:kube-controller-manager,O 为 system:kube-controller-manager,k8s里内置的ClusterRoleBindings system:kube-controller-manager 授权 kube-controller-manager 所需的权限。后面组件证书都做类似操作。生成证书命令如下
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www controller-manager-csr.json | cfssljson -bare controller-manager
- kube-scheduler
kube-scheduler 需要跟 apiserver 进行 mTLS 认证,生成证书申请文件如下
cat > /etc/kubernetes/pki/scheduler-csr.json <<EOF
{
"CN": "system:kube-scheduler",
"key": {
"algo": "rsa",
"size": 2048
},
"hosts": [
"127.0.0.1",
"192.168.122.100",
"192.168.122.101",
"192.168.122.102",
"192.168.122.101"
],
"names": [
{
"C": "CN",
"ST": "Guangdong",
"L": "Guangzhou",
"O": "system:kube-scheduler",
"OU": "system"
}
]
}
EOF
kubernetes 内置的 ClusterRoleBindings system:kube-scheduler 将授权 kube-scheduler 所需的权限。生成证书命令如下
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www scheduler-csr.json | cfssljson -bare scheduler
- kube-proxy
kube-proxy 需要跟 apiserver 进行 mTLS 认证,生成证书申请请求文件如下
cat > /etc/kubernetes/pki/proxy-csr.json <<EOF
{
"CN": "system:kube-proxy",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Guangdong",
"L": "Guangzhou",
"O": "kubernetes",
"OU": "system"
}
]
}
EOF
生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www proxy-csr.json | cfssljson -bare proxy
- 管理员admin能用的证书
创建证书信息
cat > /etc/kubernetes/pki/admin-csr.json << EOF
{
"CN": "admin",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Guangzhou",
"L": "Guangdong",
"O": "system:masters",
"OU": "system"
}
]
}
EOF
生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www admin-csr.json | cfssljson -bare admin
3.5 同步证书
生成证书之后,将证书目录/etc/kubernetes/pki同步到其他主机。
我们将使用 k8s-101、k8s-102、k8s-103 这三台主机搭建ectd集群。在撰写此文档时(2425.02.18),etcd最新稳定版本是 3.5.18,可以从 https://github.com/etcd-io/etcd/releases/ 这个链接下载对应的安装包。
4.1 etcd启动参数
常见参数说明说下
参数 | 对应环境变量 | 说明 |
–name | ETCD_NAME | 当前etcd的唯一名称,要保证和其他节点不冲突 |
–data-dir | ETCD_DATA_DIR | 指定etcd存储数据的存储位置 |
–listen-peer-urls | ETCD_LISTEN_PEER_URLS | 端对端的通信url,包含主机地址和端口号,指定当前etcd和其他节点etcd通信时的服务地址和端口。 |
–listen-client-urls | ETCD_LISTEN_CLIENT_URLS | 指定当前etcd接收客户端指令的地址和端口,在这里的客户端我们指的是k8s集群的master节点 |
–initial-advertise-peer-urls | ETCD_INITIAL_ADVERTISE_PEER_URLS | 指定etcd广播端口,当前etcd会将数据同步到其他节点,通过2380端口发送 |
–advertise-client-urls | ETCD_ADVERTISE_CLIENT_URLS | 给客户端通告的端口 |
–initial-cluster | ETCD_INITIAL_CLUSTER | 定义etcd集群中所有节点的名称和IP,以及通信端口 |
–initial-cluster-token | ETCD_INITIAL_CLUSTER_TOKEN | 定义etcd中的token,所有节点的token必须保持一致 |
–initial-cluster-state | ETCD_INITIAL_CLUSTER_STATE | 定义etcd集群的状态,new代表新建集群,existing代表加入现有集群 |
4.2 创建数据目录
先创建etcd默认的配置文件目录和数据目录
mkdir -p /var/lib/etcd/
安装到/opt目录,后续的k8s集群组件我们将都安装在此
# 解压
tar -zxvf etcd-v3.5.18-linux-amd64.tar.gz
# 将etc移到/opt目录,并修改etcd目录名
mv etcd-v3.5.18-linux-amd64/ /opt/etcd-v3.5.18
# 创建etcd软链接
ln -s /opt/etcd-v3.5.18 /opt/etcd
4.3 创建etcd启动脚本
我们先在etcd目录编写启动脚本/opt/etcd/startup.sh,如下
#!/bin/bash
./etcd \
--name="etcd-server-101" \
--data-dir="/var/lib/etcd/" \
--listen-peer-urls="https://192.168.122.101:2380" \
--listen-client-urls="https://192.168.122.101:2379,http://127.0.0.1:2379" \
--initial-advertise-peer-urls="https://192.168.122.101:2380" \
--advertise-client-urls="https://192.168.122.101:2379" \
--initial-cluster="etcd-server-101=https://192.168.122.101:2380,etcd-server-102=https://192.168.122.102:2380,etcd-server-103=https://192.168.122.103:2380" \
--initial-cluster-token="etcd-cluster" \
--initial-cluster-state="new" \
--cert-file="/etc/kubernetes/pki/etcd.pem" \
--key-file="/etc/kubernetes/pki/etcd-key.pem" \
--trusted-ca-file="/etc/kubernetes/pki/ca.pem" \
--peer-cert-file="/etc/kubernetes/pki/etcd.pem" \
--peer-key-file="/etc/kubernetes/pki/etcd-key.pem" \
--peer-trusted-ca-file="/etc/kubernetes/pki/ca.pem" \
--peer-client-cert-auth \
--client-cert-auth
给启动脚本添加权限
chmod +x /opt/etcd/startup.sh
4.4 使用supervisor来启动etcd
现在我们要安装supervisor,用于管理etcd服务,后续的k8s相关组件,我们都用supervisor来管理
# 安装supervisor
apt install supervisor -y
# 启动supervisor
systemctl start supervisor
# 让superivisor开机自启
systemctl enable supervisor
添加etcd的supervisor进程维护脚本/etc/supervisor/conf.d/etcd-server.conf,添加以下内容
[program:etcd-server-101]
directory=/opt/etcd
command=/opt/etcd/startup.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/etcd.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
注意:在不同的主机上使用不同的服务名称,这样好辨别,如k8s-101使用etcd-server-101,如k8s-102使用etcd-server-102
supervisor相关参数:
program: 程序名称directory: 脚本目录command: 启动的命令numprocs: 启动的进程数autostart: 是否开启自动启动autorestart: 是否自动重启startsecs: 启动之后多少时间后判定为已起来startretries: 重启次数exitcodes: 退出的codestopsignal: 停止信号stopwaitsecs: 停止等待的时间redirect_stderr: 是否重定向标准输出stdout_logfile: 进程标准输出内容写入文件stdout_logfile_maxbytes: stdout_logfile文件做log滚动时,单个stdout_logfile文件的最大字节数,默认50M,设置为0则认为不做log滚动方式stdout_logfile_backups: stdout_logfile备份文件个数,默认为10stdout_capture_maxbytes: 当进程处于stdout capture mode模式的时候,写入capture FIFO的最大字节数限制,默认为0,此时认为stdout capture mode模式关闭stdout_event_enabled: 如果设置为true,在进程写入标准文件是会发起PROCESS_LOG_STDOUT
更新supervisod配置文件
# 创建supervisor日志目录
mkdir -p /data/logs/supervisor/
# 更新supervisod配置
supervisorctl update
通过supervisorctl status查询supervisord状态,看到如下内容,代表supervisor正常运行
root@debian:/opt/etcd# supervisorctl status
etcd-server-101 RUNNING pid 85297, uptime 0:04:38
此时,我们再使用netstat -luntp | grep etcd查看网络服务端口,看到如下信息代表etcd已经正常启动
root@debian:/opt/etcd# netstat -luntp | grep etcd
tcp 0 0 192.168.122.101:2379 0.0.0.0:* LISTEN 85298/./etcd
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 85298/./etcd
tcp 0 0 192.168.122.101:2380 0.0.0.0:* LISTEN 85298/./etcd
4.5 集群验证
为了方便直接调用etcdctl命令,我们还可以创建其软连接
ln -s /opt/etcd/etcdctl /usr/local/bin/etcdctl
我们在任意节点使用etcdctl命令检查集群状态,需要注意的是,要确切指定证书的位置
etcdctl --cacert="/etc/kubernetes/pki/ca.pem" --cert="/etc/kubernetes/pki/etcd.pem" --key="/etc/kubernetes/pki/etcd-key.pem" --endpoints="https://192.168.122.101:2379,https://192.168.122.102:2379,https://192.168.122.103:2379" endpoint status --write-out=table
如果看到如下输出,代表 ectd 集群搭建成功
+------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| https://192.168.122.101:2379 | c8815bb4b21730b3 | 3.5.18 | 311 kB | true | false | 3 | 37628 | 37628 | |
| https://192.168.122.102:2379 | f30299e8a0b43b4d | 3.5.18 | 311 kB | false | false | 3 | 37628 | 37628 | |
| https://192.168.122.103:2379 | 61c90f737ccf2682 | 3.5.18 | 311 kB | false | false | 3 | 37628 | 37628 | |
+------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
为了验证etcd集群是否正常工作,我们还可以现在k8s-101设置一个值,如下
etcdctl put name lixiaoming123
再通过k8s-102和k8s-103去读取值,如果正常取到,代表etcd集群正常工作,如下命令
etcdctl get name
如果需要了解etcdctl这个指令的更多用法,使用--help参数即可查看。
在撰写这个文档时,kubernetes最新稳定版本为v1.32.2,所以这里也采用这个版本。通过 https://kubernetes.io/zh-cn/releases/ 下载最新的对应操作系统的稳定版本。
我们下载好对应的 "Server Binarie" 之后,在所有k8s主机上执行安装,如下步骤
# 解压安装包
tar -zxvf kubernetes-server-linux-amd64.tar.gz
# 将安装包移到/opt目录下并根据版本重命名
mv kubernetes /opt/kubernetes-v1.32.2
# 创建软连接
ln -s /opt/kubernetes-v1.32.2/ /opt/kubernetes
在k8s二进制安装目录里包含了k8s源码包,还包含k8s核心组件的docker镜像,因为我们的核心服务不运行在容器里,所以可以删除掉,操作过程如下
# 进入k8s目录
cd /opt/kubernetes
# 删除源代码
rm kubernetes-src.tar.gz
# 删除二进制文件目录下以tar作为名称后缀的docker镜像包
rm -rf server/bin/*.tar
搭建好etcd数据库集群之后,我们就可以安装apiserver组件了,在所有主机上安装apiserver,以下是具体的安装过程。
6.1 创建kubelet授权用户
因为后面要配置kubelet的bootstrap认证,即kubelet启动时自动创建CSR请求,这里需要在apiserver上开启token的认证。所以先在master上生成一个随机值作为token。下面在一台主机操作即可
# 创建证书目录
openssl rand -hex 10
假设生成的token为88c916f382dc619a6bca,把这个token写入到一个文件里,这里写入到 /etc/kubernetes/bb.csv,如下
cat > /etc/kubernetes/bb.csv <<EOF
88c916f382dc619a6bca,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
这里第二列定义了一个用户名kubelet-bootstrap,后面在配置kubelet时会为此用户授权。创建好该文件后,同步到其他主机。
6.2 启动apiser服务
6.2.1 创建启动脚本
在apiserver二进制文件目录创建/opt/kubernetes/server/bin/kube-apiserver.sh启动脚本文件,写入以下内容
#!/bin/bash
./kube-apiserver \
--v=2 \
--logtostderr=true \
--allow-privileged=true \
--bind-address="192.168.122.101" \
--secure-port="6443" \
--token-auth-file="/etc/kubernetes/bb.csv" \
--advertise-address="192.168.122.101" \
--service-cluster-ip-range="10.96.0.0/16" \
--service-node-port-range="30000-60000" \
--etcd-servers="https://192.168.122.101:2379,https://192.168.122.102:2379,https://192.168.122.103:2379" \
--etcd-cafile="/etc/kubernetes/pki/ca.pem" \
--etcd-certfile="/etc/kubernetes/pki/etcd.pem" \
--etcd-keyfile="/etc/kubernetes/pki/etcd-key.pem" \
--client-ca-file="/etc/kubernetes/pki/ca.pem" \
--tls-cert-file="/etc/kubernetes/pki/apiserver.pem" \
--tls-private-key-file="/etc/kubernetes/pki/apiserver-key.pem" \
--kubelet-client-certificate="/etc/kubernetes/pki/apiserver.pem" \
--kubelet-client-key="/etc/kubernetes/pki/apiserver-key.pem" \
--service-account-key-file="/etc/kubernetes/pki/ca-key.pem" \
--service-account-signing-key-file="/etc/kubernetes/pki/ca-key.pem" \
--service-account-issuer="https://kubernetes.default.svc.cluster.local" \
--kubelet-preferred-address-types="InternalIP,ExternalIP,Hostname" \
--enable-admission-plugins="NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,ResourceQuota" \
--authorization-mode="Node,RBAC" \
--enable-bootstrap-token-auth=true
#--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
#--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
#--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
#--requestheader-allowed-names=aggregator \
#--requestheader-group-headers=X-Remote-Group \
#--requestheader-extra-headers-prefix=X-Remote-Extra- \
#--requestheader-username-headers=X-Remote-User
赋予执行权限
chmod +x /opt/kubernetes/server/bin/kube-apiserver.sh
上面注释的部分是配置聚合层的,本环境里没有启用聚合层所以这些选项被注释了,如果配置了聚合层的话,则需要把#取消。相关参数说明
--v:日志输出级别--logtostderr:将输出记录到标准日志,而不是文件,默认是true--allow-privileged:是否使用超级管理员权限创建容器,默认为false--bind-address:绑定的IP地址,如果没有指定地址(0.0.0.0或者::),默认是 0.0.0.0,代表所有的网卡都在监听服务--secure-port:参数指定的端口号对应监听的IP地址--token-auth-file:该文件用于指定api-server颁发证书的token授权--advertise-address:向集群广播的ip地址,这个ip地址必须能被集群的其他节点访问,如果不指定,将使用–bind-address,如果不指定–bind-addres,将使用默认网卡--service-cluster-ip-range:创建service时,使用的虚拟网段--service-node-port-range:创建service时,服务端口使用的端口范围(默认 30000-32767)--etcd-cafile:访问etcd时使用,ectd的ca文件--etcd-certfile:访问etcd时使用,ectd的证书文件--etcd-servers:各个etcd节点的IP和端口号--etcd-keyfile:访问etcd时使用,ectd的证书私钥文件--client-ca-file:访问apiserver时使用,客户端ca文件--tls-cert-file:访问apiserver时使用,tls证书文件--tls-private-key-file:访问apiserver时使用,tls证书私钥文件--kubelet-client-certificate:访问kubelet时使用,客户端证书路径--kubelet-client-key:访问kubelet时使用,客户端证书私钥--service-account-key-file:包含 PEM 编码的 x509 RSA 或 ECDSA 私钥或公钥,用来检查 ServiceAccount 的令牌--service-account-signing-key-file:指向包含当前服务账号令牌发放者的私钥的文件路径。 此发放者使用此私钥来签署所发放的 ID 令牌--service-account-issuer:服务账户令牌发放者的身份标识--enable-admission-plugins:允许使用的插件--authorization-mode:授权模式--enable-bootstrap-token-auth:是否使用token的方式来自动颁发证书,如果主机节点比较多的时候,手动颁发证书可能不太现实,可以使用基于token的方式自动颁发证书
以上是我们在启动apiserver的时候常用的参数,apiserver具有很多参数,很多参数也有默认值,可以./kube-apiserver --hep命令查看更多的帮助。
6.2.2 使用supervisor运行
创建supervisor配置文件/etc/supervisor/conf.d/kube-apiserver.conf
[program:kube-apiserver-160]
directory=/opt/kubernetes/server/bin
command=/opt/kubernetes/server/bin/kube-apiserver.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/apiserver.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
更新supervisor服务
supervisorctl update
再使用supervisorctl status命令查看apiserver启动状态,如果显示如下内容,代表正常服务
此时,还可以使用netstat -luntp | grep kube-api命令查看网络服务的端口是否正常,如果正常,将返回如下内容
负载均衡是网络层的一种机制,它将请求分发到后端服务器,从而实现高可用和高性能。负载均衡器通常包含一个或多个负载均衡器,每个负载均衡器负责将请求分发到后端服务器。负载均衡器通常使用TCP或UDP协议进行通信,并通过网络层(如TCP或UDP)将请求分发到后端服务器。负载均衡器通常使用轮询、权重、会话保持等功能来优化请求分发。
现在,我们需要在k8s-101和k8s-102上安装nginx作为反向代理服务且两个服务实现负载均衡,再使用keepalived保证高可用性
7.1 安装nginx
k8s-101在安装harbor时已经安装过,需要继续在k8s-102上安装
# 安装依赖
apt install -y gcc make libpcre3-dev libssl-dev zlib1g-dev
# 下载代码
wget https://nginx.org/download/nginx-1.26.3.tar.gz
# 解压文件
tar -zxvf nginx-1.26.3.tar.gz
# 进入源码目录
cd nginx-1.26.3
# 配置编译参数,--prefix参数指定安装目录
./configure \
--prefix=/usr/local/nginx-1.26.3 \
--with-stream \
--with-http_stub_status_module \
--with-http_ssl_module --with-http_v2_module \
--error-log-path=/data/logs/nginx/error.log \
--http-log-path=/data/logs/nginx/access.log
# 编译并安装
make && make install
# 设置链接
ln -s /usr/local/nginx-1.26.3 /usr/local/nginx
ln -s /usr/local/nginx/sbin/nginx /usr/local/bin/nginx
7.2 配置nginx
安装完成之后,我们需要两台机的nginx的配置文件/usr/local/nginx/conf/nginx.conf的http节点旁边添加四层反向代码规则,将7443端口的流量使用负载均衡的方式转发到3台主机的6443端口上
# 设置代理规则
stream {
upstream kube-apiserver {
server 192.168.122.101:6443 max_fails=3 fail_timeout=30s;
server 192.168.122.102:6443 max_fails=3 fail_timeout=30s;
server 192.168.122.103:6443 max_fails=3 fail_timeout=30s;
}
server {
listen 7443;
proxy_connect_timeout 2s;
proxy_timeout 900s;
proxy_pass kube-apiserver;
}
}
在两台主机上配置好规则之后,通过nginx -t命令检查配置结果,如果输出以下内容代表配置正确
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
配置成功之后,启动nginx,如下指令
# 启动ginx,k8s-101主机使用 nginx -s reload重新加载配置即可
nginx
要让你手动编译安装的 Nginx 实现开机自启,你可以通过以下几种方式来完成(基于常见的 Linux 系统,如 Ubuntu、CentOS 等)。
7.3 使用systemd设置nginx开机自启
- 创建 Nginx 的 Systemd 服务文件
在 /etc/systemd/system/ 目录下创建一个 nginx.service 文件:
vim /etc/systemd/system/nginx.service
- 添加以下内容到服务文件中
[Unit]
Description=The NGINX HTTP and reverse proxy server
After=network.target
[Service]
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s quit
PIDFile=/usr/local/nginx/logs/nginx.pid
Restart=on-failure
Type=forking
[Install]
WantedBy=multi-user.target
- 保存并刷新
systemd配置
systemctl daemon-reload
- 设置 Nginx 开机自启并立即启动
systemctl enable nginx --now
7.4 安装keepalived
Keepalived 的虚拟 IP 通过 VRRP 协议在多个服务器间切换,确保服务高可用性和负载均衡。这个虚拟 IP 是 Keepalived 配置的 IP 地址,不属于任何特定服务器,而是由主服务器持有,主服务器故障时切换到备用服务器。我们将使用keepalived实现代理服务器的高可用,以下是安装过程
apt install keepalived -y
在两台主机的创建/etc/keepalived/check_port.sh脚本文件,添加以下内容
#!/bin/bash
CHK_PORT=$1
if [ -n "$CHK_PORT" ]; then
PORT_PROCESS=`ss -lnt|grep $CHK_PORT|wc -l`
if [ $PORT_PROCESS -eq 0 ]; then
echo "Port $CHK_PORT Is Not Used, End"
exit 1
fi
else
echo "Check Port Cant Be Empty!"
exit 1
fi
添加执行权限
chmod +x /etc/keepalived/check_port.sh
以上的操作就准备好keepalived的基础环境了,接下来我们使用k8s-101这台主机作为主节点,使用k8s-102作为重节点,进行以下配置
k8s-101作为主节点,修改/etc/keepalived/keepalived.conf配置文件如下
! Configuration File for keepalived
# 全局配置global_defs {
router_id 192.168.122.101 # 当前服务器的唯一标识,通常用 IP 地址或主机名}
# 定义健康检查脚本vrrp_script check_nginx {
script "/etc/keepalived/check_port.sh 7443" # 检查端口 7443 是否在监听的脚本 interval 2 # 每隔 2 秒执行一次脚本 weight -20 # 如果脚本检查失败,当前服务器的优先级降低 20
}
# 定义一个 VRRP 实例vrrp_instance VI_1 {
state MASTER # 当前服务器的初始状态是 MASTER(主服务器) interface enp1s0 # 绑定虚拟 IP 的网络接口 virtual_router_id 251 # VRRP 实例的唯一 ID,范围是 1-255
priority 100 # 当前服务器的优先级,数值越大优先级越高 advert_int 1 # 每隔 1 秒发送一次 VRRP 通告 mcast_src_ip 192.168.122.101 # 发送 VRRP 通告的源 IP 地址 nopreempt # 如果主服务器挂了又恢复,不会抢占虚拟 IP
# 认证配置 authentication {
auth_type PASS # 认证类型为密码认证 auth_pass 1111 # 认证密码 }
# 虚拟 IP 地址配置 virtual_ipaddress {
192.168.122.100 # 虚拟 IP 地址,主服务器会持有这个 IP
}
}
k8s-102作为从节点,修改/etc/keepalived/keepalived.conf配置文件如下
! Configuration File for keepalived
global_defs {
router_id 192.168.122.102
}
vrrp_script check_nginx {
script "/etc/keepalived/check_port.sh 7443"
interval 2
weight -20
}
vrrp_instance VI_1 {
state BACKUP
interface enp1s0
virtual_router_id 251
priority 90
advert_int 1
mcast_src_ip 192.168.122.101
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.122.100
}
}
启动服务
# 重启服务
systemctl restart keepalived
# 设置服务为开机自启
systemctl enable keepalived
需要注意的是,interface参数对应的是真实的主机网卡名称,virtual_router_id参数需要在同一个虚拟IP的前提下,设置需与主机一个网段的IP。
7.5 验证
通过ping 192.168.122.100的方式进行验证,如果有正常返回,代表keepalived运行正常。
为了验证 Keepalived 的高可用性,可以手动模拟主服务器故障,观察虚拟 IP 是否切换到备用服务器。
- (1)停止主服务器的 Keepalived 服务
在主服务器上执行:
systemctl stop keepalived
- (2)检查备用服务器的虚拟 IP
在备用服务器上执行:
ip addr show
检查虚拟 IP 是否绑定到备用服务器的网卡。
- (3)恢复主服务器的 Keepalived 服务
在主服务器上执行:
systemctl start keepalived
再次检查虚拟 IP 是否切换回主服务器。如果以上操作正常,则说明 Keepalived 的高可用性已经实现,否则需要检查安装过程以及 Keepalived 的配置文件,确保所有参数设置正确。
8.1 创建kubectl链接
kubectl 是k8s的管理工具,我们创建一个软链接,方便后续使用,如下
ln -s /opt/kubernetes/server/bin/kubectl /usr/local/bin/kubectl
8.2 安装controller-manager
8.2.1 创建配置
controller-manager 和 apiserver 之间的认证是通过 kubeconfig 的方式来认证的,即 controller-manager 的私钥、公钥及CA的证书要放在一个 kubeconfig 文件里。下面创建controller-manager所用的kubeconfig文件kube-controller-manager.kubeconfig,现在在/etc/kubernetes/pki里创建,然后移动到/etc/kubernetes里。
# 进入证书目录
cd /etc/kubernetes/pki/
# 设置集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.122.100:7443 --kubeconfig=kube-controller-manager.kubeconfig
# 设置用户信息,这里用户名是system:kube-controller-manager ,也就是前面controller-manager-csr.json里CN指定的。
kubectl config set-credentials system:kube-controller-manager --client-certificate=controller-manager.pem --client-key=controller-manager-key.pem --embed-certs=true --kubeconfig=kube-controller-manager.kubeconfig
# 设置上下文信息
kubectl config set-context system:kube-controller-manager --cluster=kubernetes --user=system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig
# 设置默认的上下文
kubectl config use-context system:kube-controller-manager --kubeconfig=kube-controller-manager.kubeconfig
# 将生成的证书移到/etc/kubernetes/
mv kube-controller-manager.kubeconfig /etc/kubernetes/
/etc/kubernetes/kube-controller-manager.kubeconfig配置文件只需生成一次,再传到其他主机即可。
8.2.2 创建启动脚本
创建文件/opt/kubernetes/server/bin/kube-controller-manager.sh,添加以下内容
#!/bin/bash
./kube-controller-manager \
--v=2 \
--logtostderr=true \
--bind-address=127.0.0.1 \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-private-key-file=/etc/kubernetes/pki/ca-key.pem \
--kubeconfig=/etc/kubernetes/kube-controller-manager.kubeconfig \
--leader-elect=true \
--use-service-account-credentials=true \
--node-monitor-grace-period=40s \
--node-monitor-period=5s \
--controllers=*,bootstrapsigner,tokencleaner \
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \
--node-cidr-mask-size=24
添加执行权限与创建日志目录
# 添加可执行权限
chmod +x /opt/kubernetes/server/bin/kube-controller-manager.sh
创建supervisor脚本启动管理文件/etc/supervisor/conf.d/kube-controller-manager.conf,添加以下内容
[program:kube-controller-manager-101]
directory=/opt/kubernetes/server/bin
command=/opt/kubernetes/server/bin/kube-controller-manager.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/controller.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
更新supervisor
supervisorctl update
9.1 创建配置
scheduler 和 apiserver 之间的认证也是通过 kubeconfig 的方式来认证的,下面创建 scheduler 所用的 kubeconfig 文件 kube-scheduler.kubeconfig,现在在/etc/kubernetes/pki里创建,然后剪切到/etc/kubernetes里。
# 进入证书目录
cd /etc/kubernetes/pki/
# 设置集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.122.100:7443 --kubeconfig=kube-scheduler.kubeconfig
# 设置用户信息
kubectl config set-credentials system:kube-scheduler --client-certificate=scheduler.pem --client-key=scheduler-key.pem --embed-certs=true --kubeconfig=kube-scheduler.kubeconfig
# 设置上下文信息
kubectl config set-context system:kube-scheduler --cluster=kubernetes --user=system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig
# 设置默认的上下文
kubectl config use-context system:kube-scheduler --kubeconfig=kube-scheduler.kubeconfig
# 剪切到/etc/kubernetes
mv kube-scheduler.kubeconfig /etc/kubernetes/
/etc/kubernetes/kube-scheduler.kubeconfig配置文件也只需生成一次,再传到其他主机即可。
9.2 创建启动脚本
创建scheluder启动脚本文件/opt/kubernetes/server/bin/kube-scheduler.sh文件,添加以下内容
#!/bin/bash
./kube-scheduler \
--v=2 \
--bind-address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/kube-scheduler.kubeconfig
添加脚本执行权限与创建日志目录
# 添加脚本的可执行权限
chmod +x /opt/kubernetes/server/bin/kube-scheduler.sh
创建进程管理配置文件/etc/supervisor/conf.d/kube-scheduler.conf文件,添加以下内容
[program:kube-scheduler-101]
directory=/opt/kubernetes/server/bin
command=/opt/kubernetes/server/bin/kube-scheduler.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/scheduler.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
更新supervisor
supervisorctl update
10.1 创建管理员配置
创建管理员用户用的kubeconfig,最后拷贝为 ~/.kube/config 作为默认的kubeconfig文件。
# 进入证书目录
cd /etc/kubernetes/pki/
# 设置一个集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.122.100:7443 --kubeconfig=admin.conf
# 设置用户信息
kubectl config set-credentials admin --client-certificate=admin.pem --client-key=admin-key.pem --embed-certs=true --kubeconfig=admin.conf
# 设置上下文
kubectl config set-context kubernetes --cluster=kubernetes --user=admin --kubeconfig=admin.conf
# 设置默认上下文境
kubectl config use-context kubernetes --kubeconfig=admin.conf
# 移动
mv admin.conf /etc/kubernetes/
创建好之后同步到其他节点,再拷贝配置文件到用户目录。
10.2 使用管理员配置
mkdir -p ~/.kube
cp /etc/kubernetes/admin.conf ~/.kube/config
使用kubectl get cs检查集群状态,这时候你会发现类似如下的错误
Error from server (Forbidden): Forbidden (user=admin, verb=get, resource=nodes, subresource=proxy)
这代表我们创建的admin用户没有集群管理权限,绑定一个cluster-admin角色即可,如下命令
kubectl create clusterrolebinding system:anonymous --clusterrole=cluster-admin --user=admin
最后再使用kubectl get cs查看集群,如返回以下类似内容,则代表集群控制节点的服务正常
root@k8s-101:~# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok
不过这个命令将来可能会被废弃,目前也可以使用 kubectl cluster-info 命令查看 Kubernetes 集群的基本信息。
11.1 创建授权配置文件
为用户 kubelet-bootstrap 授权,允许 kubelet tls bootstrap 创建 CSR 请求,执行如下命令
kubectl create clusterrolebinding kubelet-bootstrap1 --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
把 system:certificates.k8s.io:certificatesigningrequests:nodeclient 授权给 kubelet-bootstrap,目的是实现对 CSR 的自动审批,如下命令
kubectl create clusterrolebinding kubelet-bootstrap2 --clusterrole=system:certificates.k8s.io:certificatesigningrequests:nodeclient --user=kubelet-bootstrap
这个用户名是在配置 apiserver 时用到的token文件/etc/kubernetes/bb.csv里指定的。最后使用以下命令创建对应授权配置文件
# 进入证书目录
cd /etc/kubernetes/pki/
# 创建集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.122.100:7443 --kubeconfig=kubelet-bootstrap.conf
# 创建用户信息,注意token是上面创建的`bb.csv`里指定的token
kubectl config set-credentials kubelet-bootstrap --token=e83b6b5f1d1dba4cf38a --kubeconfig=kubelet-bootstrap.conf
# 设置上下文
kubectl config set-context kubernetes --cluster=kubernetes --user=kubelet-bootstrap --kubeconfig=kubelet-bootstrap.conf
# 启用上下文
kubectl config use-context kubernetes --kubeconfig=kubelet-bootstrap.conf
# 剪切配置文件到/etc/kubernetes
mv kubelet-bootstrap.conf /etc/kubernetes/
生成配置文件/etc/kubernetes/kubelet-bootstrap.conf之后,传到工作节点中,在这里是k8s-102和k8s-103。
11.2 创建kubelet配置文件
创建 kubelet 用到的配置文件 /etc/kubernetes/kubelet-config.yaml,后续 kubelet 配置启动文件需要用到,内容如下
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.96.0.10
clusterDomain: cluster.local
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
kind: KubeletConfiguration
podInfraContainerImage: "registry.aliyuncs.com/google_containers/pause:3.10"
这里我们指定clusterDNS的IP是10.96.0.10,后续我们会在kube-dns中配置CoreDNS的IP为10.96.0.10。
11.3 配置kubelet启动脚本
11.3.1 配置启动脚本
接下来在k8s-102和k8s-103上启动kubelet,在让kubelet启动之前,我们需要有一个基础的pause镜像,以下是拉取命令,该镜像负责其k8s集群中pod启动之前的初始化操作
nerdctl pull registry.aliyuncs.com/google_containers/pause:3.10
创建kubelet的启动脚本文件/opt/kubernetes/server/bin/kubelet.sh文件,添加以下内容
#!/bin/bash
./kubelet \
--bootstrap-kubeconfig=/etc/kubernetes/kubelet-bootstrap.conf \
--cert-dir=/var/lib/kubelet/pki \
--hostname-override=k8s-102 \
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \
--config=/etc/kubernetes/kubelet-config.yaml \
--v=2
添加可执行权限
chmod +x /opt/kubernetes/server/bin/kubelet.sh
创建数据目录和日志目录
# 创建kubelet所需要的日志目录
mkdir -p /var/log/kubernetes
11.3.2 配置管理服务
创建supervisor进程配置文件/etc/supervisor/conf.d/kube-kubelet.conf文件,添加以下内容
[program:kube-kubelet-102]
directory=/opt/kubernetes/server/bin
command=/opt/kubernetes/server/bin/kubelet.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/kubelet.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
更新supervisord,如下命令
supervisorctl update
11.3.3 验证集群
此时,服务已经正常运行了,可以使用以下kubectl命令在查看节点信息
kubectl get nodes
如果看到以下信息,代表安装成功
NAME STATUS ROLES AGE VERSION
k8s-102 Ready <none> 19m v1.32.2
k8s-103 Ready <none> 18m v1.32.2
我们还可以设置集群的标签
# 设置集群为node标签
kubectl label node k8s-102 node-role.kubernetes.io/node=
kubectl label node k8s-103 node-role.kubernetes.io/node=
12.1 创建kubeconfig配置文件
在k8s-101服务器上执行,如下命令
# 进入证书目录
cd /etc/kubernetes/pki/
# 创建集群信息
kubectl config set-cluster kubernetes --certificate-authority=ca.pem --embed-certs=true --server=https://192.168.122.100:7443 --kubeconfig=kube-proxy.kubeconfig
# 创建用户信息
kubectl config set-credentials kube-proxy --client-certificate=proxy.pem --client-key=proxy-key.pem --embed-certs=true --kubeconfig=kube-proxy.kubeconfig
# 创建上下文
kubectl config set-context default --cluster=kubernetes --user=kube-proxy --kubeconfig=kube-proxy.kubeconfig
# 应用上下文
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
# 移动到/etc/kubernetes/
mv kube-proxy.kubeconfig /etc/kubernetes/
创建完成后,同步到工作节点192-debian和160-debian。
12.2 创建kube-proxy配置文件
在工作节点创建/etc/kubernetes/kube-proxy.yaml,内容如下
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
clientConnection:
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
clusterCIDR: 10.244.0.0/16
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0:10249
mode: "ipvs"
12.3 创建启动脚本
在两台主机执行以上脚本之后,我们创建kube-proxy的启动脚本文件/opt/kubernetes/server/bin/kube-proxy.sh
#!/bin/bash
./kube-proxy \
--config=/etc/kubernetes/kube-proxy.yaml \
--v=2
添加可执行权限
chmod +x /opt/kubernetes/server/bin/kube-proxy.sh
13.4 创建服务配置
创建supervisor的配置文件/etc/supervisor/conf.d/kube-proxy.conf文件,添加以下内容
[program:kube-proxy-102]
directory=/opt/kubernetes/server/bin
command=/opt/kubernetes/server/bin/kube-proxy.sh
numprocs=1
autostart=true
autorestart=true
startsecs=30
startretries=3
exitcodes=0,2
stopsignal=QUIT
stopwaitsecs=10
user=root
redirect_stderr=true
stdout_logfile=/data/logs/supervisor/kube-proxy.stdout.log
stdout_logfile_maxbytes=64MB
stdout_logfile_backups=4
stdout_capture_maxbytes=1MB
stdout_event_enabled=false
更新supervisor
supervisorctl update
12.5 创建权限配置文件
kube-proxy 是 Kubernetes 集群中的一个核心组件,负责在每个节点上维护网络规则,确保 Pod 之间的网络通信。为了实现这一功能,kube-proxy 需要与 Kubernetes API Server 进行交互,获取集群的网络信息(如 Service、Endpoint 等),并根据这些信息配置本地的网络规则(如 iptables 或 ipvs)。为了与 API Server 交互,kube-proxy 需要一定的权限,特别是访问节点资源的权限。
RBAC(基于角色的访问控制)是 Kubernetes 中用于管理权限的机制。通过创建 RBAC 配置,kube-proxy 被授予了以下权限:访问 nodes/proxy、nodes/stats、nodes/log 等资源,以便获取节点的网络和状态信息。执行相关操作(如 get、list、watch 等)来维护网络规则。如果没有这些权限,kube-proxy 将无法正常工作,导致集群中的网络功能失效。因此,启动 kube-proxy 之后创建 RBAC 配置是必要的。
在k8s-101上创建/etc/kubernetes/rbac.yaml,写入如下内容
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kubernetes-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kubernetes
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kubernetes-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
12.6 创建角色及授权
kubectl apply -f /etc/kubernetes/rbac.yaml
12.7 集群的验证
在两个节点都启动好kube-proxy服务之后,至此,集群的基本组件已经安装完成,下面我们来验证集群。在任意管理节点创建一个Pod类型的资源,添加nginx-pod.yml文件,添加以下内容
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
containers:
- name: nginx-pod
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- name: nginxport
containerPort: 80
执行资源创建命令
kubectl create -f nginx-pod.yml
使用以下命令验证pod是否正常运行
kubectl get pod -o wide
如果返回如下内容,代表集群正常
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 94s 10.22.0.2 k8s-103 <none> <none>
创建的pod运行在k8s-103这台主机上,在这台机使用curl 10.22.0.2命令能正常访问到nginx服务。但是如果我们在另一个节点k8s-102上执行curl 10.22.0.2会发现访问不到。原因是这两个节点上的容器在各自的虚拟网络内,我们将到后续的章节安装通过安装 k8s 网络插件的方式,实现不同工作节点的容器网络互相访问的功能。
以下的操作,我们在k8s-101节点去完成。
13.1 安装calico
Calico 是 Kubernetes 集群的网络基础设施,负责 Pod 的网络连接、跨节点通信和网络策略管理。根据以下步骤进行安装。
cd /etc/kubernetes
wget https://docs.projectcalico.org/manifests/calico.yaml
修改calico.yaml文件,将CALICO_IPV4POOL_CIDR改为和kube-proxy的配置一样,如下
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
在calico配置文件中,定义了一下容器镜像,在运行calico的时候将会用到,可以使用 cat calico.yaml | grep image 命令查看所有需要的镜像列表,如下
image: docker.io/calico/cni:v3.25.0
imagePullPolicy: IfNotPresent
image: docker.io/calico/cni:v3.25.0
imagePullPolicy: IfNotPresent
image: docker.io/calico/node:v3.25.0
imagePullPolicy: IfNotPresent
image: docker.io/calico/node:v3.25.0
imagePullPolicy: IfNotPresent
image: docker.io/calico/kube-controllers:v3.25.0
imagePullPolicy: IfNotPresent
我们可以看到,这些镜像都来自docker.io,但因为一些原因,在撰写这篇文档时,国内访问 docker.io 的网络不太顺畅。因此你需要想办法让你的工作节点宿主机能拉取到这些镜像,最后再创建calico服务。或者你需要修改配置文件,改成这些镜像在可以拉取到的国内镜像站对应的镜像名。
解决依赖的镜像的拉取问题后,最后创建calico服务
kubectl apply -fcalico.yaml
执行命令之后,calico会拉去远端的镜像并运行,执行 kubectl get pods -n kube-system 等到所有pod都处于Running状态代表服务启动完成,如下
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6799f5f4b4-xqpf9 1/1 Running 0 3m34s
calico-node-9bt29 1/1 Running 0 3m34s
calico-node-djxvc 1/1 Running 0 3m34s
此时calico已经正常运行了,如果上节创建的nginx的pod还没有删除的话,先删除掉再创建,如下命令
kubectl delete -f nginx-pod.yaml
kubectl apply -f nginx-pod.yaml
创建新的pod之后,使用kubectl get pod -o wide查看pod所处的节点,此时我们在任意工作节点请求该IP,都能成功请求。
13.2 安装coredns
CoreDNS 是 Kubernetes 集群的 DNS 服务,负责为集群内的服务提供域名解析和服务发现功能,使得 Pod 可以通过服务名称访问其他服务。它允许 Pod 通过服务名称(如 my-service.default.svc.cluster.local)来访问其他服务,而不需要知道具体的 IP 地址。
13.2.1 下载基础资源配置文件
下载corndns资源配置文件
cd /etc/kubernetes
wget https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/dns/coredns/coredns.yaml.base -O coredns.yml
13.2.2 修改配置
做出以下修改:
找到配置文件中的__DNS__DOMAIN__这两个变量改为集群域名,如下
kubernetes cluster.local in-addr.arpa ip6.arpa {
fallthrough in-addr.arpa ip6.arpa
}
将 __DNS__MEMORY__LIMIT_ 改为512Mi,如下
将__DNS_SERVER__改为kubelet配置文件中指定的集群IP地址10.96.0.10,如下
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.96.0.10
13.2.3 启动服务
使用以下命令启动服务
kubectl apply -f coredns.yml
14.1 启动traefik服务
Traefik 在 Kubernetes (k8s) 中的作用主要是作为反向代理和负载均衡器,负责管理外部流量到集群内部服务的路由。我们先定义 traefik 的资源,在/etc/kubernetes目录下创建traefik.yml文件,添加以下内容
apiVersion: v1
kind: ServiceAccount
metadata:
name: traefik-ingress-controller
namespace: kube-system
---
# 定义角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: traefik-ingress-controller
rules:
- apiGroups:
- ""
resources:
- services
- endpoints
- secrets
verbs:
- get
- list
- watch
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses
- ingressclasses
verbs:
- get
- list
- watch
- apiGroups:
- extensions
- networking.k8s.io
resources:
- ingresses/status
verbs:
- update
---
# 创建角色和账号绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: traefik-ingress-controller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: traefik-ingress-controller
subjects:
- kind: ServiceAccount
name: traefik-ingress-controller
namespace: kube-system
---
# 创建traefik服务
apiVersion: apps/v1
kind: Deployment
metadata:
name: traefik
namespace: kube-system
labels:
app: traefik
spec:
replicas: 1
selector:
matchLabels:
app: traefik
template:
metadata:
labels:
app: traefik
spec:
serviceAccountName: traefik-ingress-controller
containers:
- name: traefik
image: traefik:v2.10
ports:
- name: web
containerPort: 80
- name: websecure
containerPort: 443
- name: admin
containerPort: 8080
args:
- --api.insecure=true
- --providers.kubernetesingress
- --entrypoints.web.Address=:80
- --entrypoints.websecure.Address=:443
---
# 创建traefik的service
apiVersion: v1
kind: Service
metadata:
name: traefik
namespace: kube-system
spec:
type: NodePort
ports:
- name: http
port: 80
nodePort: 58180
- name: https
port: 443
nodePort: 58181
- name: dashboard
port: 8080
nodePort: 58182
selector:
app: traefik
基于traefik镜像启动的pod将创建运行三个端口服务,80和443对应ingress本身核心服务,我们后续可以将流量都转发到ingress的80端口,让ingress做流量调度。8080是traefik的控制面板后台服务。
我们定义了3个nodePort类型的service,目的是为了在每个工作节点上提供一个服务入口。后续再将请求负载到各个节点上。创建好配置文件后,执行以下命令启动服务
kubectl apply -f traefik.yml
此时我们通过 kubectl get svc -A -o wide | grep traefik 命令可以看到如下结果
kube-system traefik NodePort 10.96.71.38 <none> 80:58180/TCP,443:58181/TCP,8080:58182/TCP 116s
我们可以使用ipvsadm -L查看所有端口映射关系,现在我们在浏览器访问不同的工作节点上IP的58180端口,都会看到traefik的管理页面,代表安装成功。我们可以看到,集群节点端口与trafik端口的对应关系如下:
集群节点端口 | Traefik端口 |
58180 | 80 |
58181 | 443 |
58182 | 8080 |
集群节点的端口由我们自定义,而traefik的8080端口是控制面板端口,80和443则是常见web服务的默认端口。
14.2 配置负载均衡
我们在k8s-101、k8s-102节点上分别创建了nginx服务,现在我们将流量转发到这2个工作节点上,假设我们的业务服务器是algs.tech,在nginx服务器添加以下配置
upstream traefik_dashboard {
server 192.168.122.102:58182 max_fails=3 fail_timeout=10s;
server 192.168.122.103:58182 max_fails=3 fail_timeout=10s;
}
server {
server_name traefik.algs.tech;
location / {
proxy_pass http://traefik_dashboard;
proxy_set_header Host $http_host;
proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for;
}
}
upstream traefik_http {
server 192.168.122.102:58180 max_fails=3 fail_timeout=10s;
server 192.168.122.103:58180 max_fails=3 fail_timeout=10s;
}
server {
server_name *.algs.tech;
listen 80;
location / {
proxy_pass http://traefik_http;
proxy_set_header Host $http_host;
proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for;
}
}
upstream traefik_https {
server 192.168.122.102:58181 max_fails=3 fail_timeout=10s;
server 192.168.122.103:58181 max_fails=3 fail_timeout=10s;
}
server {
server_name *.algs.tech;
listen 443 ssl;
# ssl证书
ssl_certificate /etc/certs/ssl/algs.tech/fullchain.pem;
ssl_certificate_key /etc/certs/ssl/algs.tech/key.pem;
ssl_session_timeout 5m;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_session_cache shared:SSL:10m;
ssl_prefer_server_ciphers on;
location / {
proxy_pass http://traefik_https;
proxy_set_header Host $http_host;
proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for;
}
}
在以上配置中,我们把traefik.algs.tech的请求转发到traefik的控制面板。同时,我们把*.algs.tech的所有80端口和443端口的流量转发到集群对应的traefik服务,由traefik来调度,后续发布服务我们只需要配置好 ingress 资源即可。
至此,集群的核心组件和核心插件已经全部安装完毕。
在本节中,我们将部署一个简单的web服务,并通过ingress资源来发布到集群中。
15.1 概述
部署k8s通常包含以下几个步骤
- 1.准备项目镜像,用于启动应用容器
- 2.通常创建Deployment资源的方式运行应用
- 3.创建应用的Service网络,用于关联Deployment
- 4.创建对应的Ingress资源,用于调度7层流量
在下文,我们使用声明式的管理方式(通常指通过yaml配置文件来管理集群)来创建各个集群资源,完成应用部署。
15.2 准备资源配置文件
我们通过部署 nginx 来演示一个应用在k8s部署的流程
15.2.1 声明deployment
创建whoami.yml文件,添加以下内容
kind: Deployment
apiVersion: apps/v1
metadata:
name: whoami
labels:
app: whoami
spec:
replicas: 1
selector:
matchLabels:
app: whoami
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: whoami
image: nginx
ports:
- name: web
containerPort: 80
15.2.2 声明service
创建whoami-services.yml文件,添加以下内容
apiVersion: v1
kind: Service
metadata:
name: whoami
spec:
ports:
- name: web
port: 80
targetPort: web
selector:
app: whoami
15.2.3 声明ingress
创建whoami-ingress.yml,添加以下内容
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: whoami-ingress
spec:
rules:
- host: nginx.algs.tech
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: whoami
port:
name: web
15.3 资源创建与验证
创建各个资源
kubectl apply -f whoami.yml \
-f whoami-services.yml \
-f whoami-ingress.yml
执行以上命令之后,k8s将会拉取 nginx 的镜像,并按我们指定的配置去启动服务。
启动完成之后,我们在自己的桌面操作系统的电脑上将nginx.algs.tech域名解析到在前面通过 keepalived 创建的虚拟IP 192.168.122.100,再使用浏览器访问域名,就顺利访问到了nginx的首页了。